Machine Learning Security: a new crop of technologies
Artificial Intelligence (AI), and Machine Learning (ML) specifically, are now at the stage in which we start caring about their security implications. Why now? Because that’s the point at which we usually start caring about the security considerations of new technologies we’ve started using. Looking at previous cases, such as of desktop computing, the Internet, car networks, and IoT (Internet of Things), those technologies first gained fast momentum by the urge to capitalize on their novel use-cases. They were deployed as fast as they could possibly be, by stakeholders rushing to secure their share of the emerging revenue pie. Once the systems started operating en masse, it was finally time to realize that where there is value – there is also malice, and every technology that processes an asset (valuable data that can be traded, the ability to display content to a user and grab her attention, potential for extortion money, etc.) will inevitably lure threat actors who demonstrate impressive creativity when attempting to divert or exploit those assets.
This flow of events is barely surprising, and we were not really shocked to learn that the Internet does not provide much security out of the box, that cars could be hacked remotely through their wireless interfaces, or that cheap home automation gear doesn’t bother to encrypt its traffic. This is economy, and unless there is an immediate public safety issue causing the regulator to intervene (often later than it should), we act upon security considerations only once the new technology is deployed, and the security risks are manifested in a way that they can no longer be ignored.
It happened with desktop computing in the 80’s, with the Internet in the 90’s, with car networks about a decade ago, and with mass IoT about half a decade ago. (In those approximate dates I am not referring to when the first security advocate indicated that there are threats, this usually happened right away if not before, but to when enough security awareness was built for the industry to commit resources towards mitigating some of those threats.) Finally, it’s now the turn of Machine Learning.
When we decide that a new technology “needs security” we look at the threats and see how we can address them. At this point, we usually divide into two camps:
-
Some players, such as those heavily invested in securing the new technology, and consultants keen on capitalizing on the new class of fear that the industry just brought on itself, assert that “this is something different”; everything we knew about security has to be re-learned, and all tools and methodologies that we’ve built no longer suffice. In short, the sky is falling and we’re for the rescue.
-
Older security folks will point at the similarities, concluding that it’s the same security, just with different assets, requirements, and constraints that need to be accounted for. IoT Security is the same security just with resource constrained devices, physical assets, long device lifetime, and harsh network conditions; car security is the same security with a different type of network, different latency requirements, and devastating kinetic effects in case of failure, and so forth.
I usually associate with the second camp. Each new area of security introduces a lot of engineering work, but the basic paradigms remain intact. It’s all about securing computer systems, just with different properties. Those different properties make tremendous differences, and call for different specializations, but the principles of security governance, and even the nature of the high-level objectives, are largely reusable.
With Machine Learning the situation is different. This is a new flavor of security that calls for a new crop of technologies and startups that deploy a different mindset towards solving a new set of security challenges; including challenges that are not at focus in other domains. The remainder of this post will delve into why ML Security is different (unlike the previous examples), and what our next steps could look like when investing in mitigation technologies.
Problem statement
As a quick clarification, the challenge we’re discussing is ‘securing ML’, rather than ‘using ML for Security’. This is a critical distinction to be made. ML/AI for Security is about using Machine Learning to augment security technologies that protect something else, such as using ML to detect malware. If you are interested in this topic, please refer to two other posts I wrote: “An obvious limitation of machine-learning for security” and “Addressing the shortcoming of machine-learning for security”. This time, we discuss the need to secure the Machine-Learning systems themselves.
Securing ML is also a wide topic. A useful piece discussing some of its aspects is “Hacking Super Intelligence” by Guy Harpak. I focus on one aspect of it which is the protection of the logic against targeted contamination (or: poisoning). Those are attacks that attempt to cause an ML system to trigger decisions that are favorable to the attacker (and violating the intent of the owner) by introducing fake data into the training phase. The discussion also applies to evasion, which refers to an attacker foiling the system at runtime (post-training) without being able to affect the training data. There are other attacks as well, and particularly all attacks that every computer system is subject to. Those are all interesting, of course, but will be kept out of scope for now.
How is ML Security different? – By objectives and by ‘kill-chain’
It is with a heavy heart that I mention the term ‘kill-chain’. Truth be told, I am not a big fan of this term, because it attempts to condense a wide domain into a single enumeration of phases which do not always apply. Really, this blog exists for 15 years, during which I used this term maybe once before. Nevertheless, this notion of a ‘kill-chain’ does come in handy here, as it offers a list of the points at which the system designer and the attacker interact. Technologies and products are classified by the stages in the ‘kill-chain’ that they tackle, so showing the dissimilarity of ‘kill-chains’ drives home the message that ML Security requires different approaches.
At the highest level, ML Security shall not be different than any other form of Security, given that Security means protecting against “bad things happening”, with “bad things” defined in objectives (see my post on security governance). When it comes to actually implementing Security, however, traditional Security focuses on logic being altered, or tricked into behaving in unintended ways. ML Security has all of that, but it has another element, which is the need to defend against that logic being abused (without necessarily being violated). Indeed, traditional Security also has to defend against abuse, but those aspects of abused logic are less complex to model and usually harder to exploit in all those systems that do not use their inputs to learn how to act. One may thus see ML Security as a domain in which the act on input aspect of security engineering is magnified in its complexity, to become the biggest part of the threat landscape. If you carelessly define the security objectives for your ML system without considering that it is an ML system, you may experience hacks that are successful without causing the logic to deviate from its intended operation, and oddly enough: without violating any of its security objectives at all!
Coming down from the high-level discussion, let us delve a bit into the ‘kill-chain’. This illustration shows the traditional ‘kill-chain’ (taken from here) on the left, and an envisioned ‘kill-chain’ for ML poisoning on the right (no reference here – I made it up.)
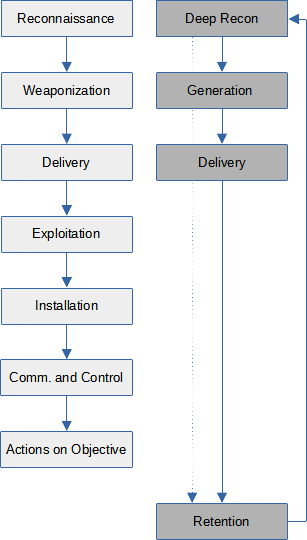 (Traditional vs. ML Kill-Chain)
(Traditional vs. ML Kill-Chain)
We can see that some active steps that are involved in a traditional ‘kill-chain’ do not exist in the context of ML poisoning:
-
exploitation and installation do not occur, because the attacker does not alter the system at all,
-
command-and-control also does not happen, because the attacker does not interact with the system directly and has no business tinkering with its logic, and finally:
-
action on objectives is not actively carried out, because the actions to be taken per the attacker’s objectives are autonomously taken by the system itself, which makes some of its beauty.
Having fewer boxes does not imply less work, however. Consider, for example, the following challenges.
-
Reconnaissance (changed into ‘Deep Reconnaissance’) requires not just learning what components exist and where, but also much of their state, and the generic logic by which this state gets updated. Before downplaying this part, imagine uncovering how Google page-ranks are calculated. As opposed to page ranking, other algorithms may be public, but their state seldom is; spam filtering makes a good example.
-
Retention is required, which implies that the reconnaissance phase never ends. A Machine Learning system keeps learning; from the attacker’s perspective this is a double-edged sword – this is how he got in, but this is also how he may be kicked out.
-
Delivery may either be easier or harder, depending on what needs to be delivered. By the original ‘kill-chain’, delivery is of exploit code. In ML, it is data that will be used for training the model. Moreover, in the ML context there is also the corollary attack of ‘non-delivery’. Sometimes it is easier for an active attacker to prevent training data from being introduced into the system than it is to address the effect of this data later.
Finally, this discussion cannot be complete without mentioning that ML systems are computer systems at their core. Hence, the ‘kill-chain’ for ML poisoning shall be seen as adding to the ordinary one, rather than replacing it.
A quick example
As a quick illustration, let us take the case of the two students who foiled Waze into detecting a traffic jam where there wasn’t one, as reported by Wired. In this attack:
-
Deep Reconnaissance was easy: the logic that Waze uses is trivial to anticipate to a useful extent, and the current state of the logic is data one can easily do without (for this type of an attack).
-
Generation was not trivial, as the article points out, but was doable by two students. Determining what data needs to be generated was the easy part. The harder part was emulating this data as coming from the GPS – barely a challenge for a serious hacker.
-
Delivery was challenging, and required finding an exploit that allowed mass fake devices to be enrolled into the service. Real opponents with financial motives use bots even against better-protected targets as Facebook, so Delivery in this case is probably a no-biggie either.
-
Retention was not attempted. The students proved their point, notified the company, and called it a day. Retention could be challenging if Waze found ways to prune false accounts, or used some logic to require a more sophisticated Generation phase that will make the attack not worth the effort.
This was an easy case, but it was carried out by two software engineering students (not even Security), and their advisor, who was also an ML (rather than Security) pro. Hacking other ML systems is likely to be harder, but remember that if there is sufficient monetary incentive, then an ecosystem of service providers is likely to also emerge. This can be comparable to contemporary SEO firms that cause (or promise to cause) the Google page-rank algorithm to promote any page at any URL you give them, for a monthly fee. All the Generation, Delivery, and Retention is done for you behind the scenes, as a service.
The novel ML Security initiatives
The final word on ML Security has not yet been said, and probably the first one has not yet been said either; and yet a large industry awaits this word.
I anticipate that as ML Security gains traction, we will see new technologies focusing on elements of the ML ‘kill-chain’, trying to address them in a way that is as portable between ML use-cases as it could possibly be. For example:
-
The Delivery phase will likely be mitigated to a large extent by securing the supply-chain of data. (I may be tempted to write a dedicated post on it one day.) This may be a low-hanging fruit, also because some of the technologies providing such protection may already be within the state of the art. This is also a place where hardware can play a critical role in making this goal attainable also in low-latency environments.
-
The Reconnaissance phase may be addressed in different ways, some of which are based on technologies which are within the state of the art, such as:
-
methods of protecting intellectual property within the logic of a running system (see the Google page-rank example mentioned earlier; the challenge would be to provide such protection on endpoints that do not enjoy the security posture of a Google server),
-
methods of throttling information leakage via queries, as experimented today in privacy preserving systems,
-
traditional means of protecting data at-rest and at run-time, considering that traditional attacks can be used to accomplish phases in ML attacks; for example, a server can be hacked to gain state data.
-
In some cases, preventing Reconnaissance cannot be used to block attacks at all, as reconnaissance may not even be needed by the attacker. It has been shown that deep learning attacks can often be devised without knowing the model.
Those are some low-hanging fruits. Higher fruits are still a bit sour, such as algorithmic ways of reacting to poisoning without hampering the versatility of the ML system. But ML is already here, and research will pace at a level that may either suffice or not. What the industry typically does when there are no silver bullets is revert to per-use-case modelling, in order to devise bullets that are not silver, but which are well aimed and solve enough of the problem for the particular cases of immediate interest. When you see a network utilizing several security products to protect against, say, ransomware (or malware in general), this is the result of lack of a one-size-fits-all solution. Each network models its own risks and requirements, and devises its own solution using a set of off-the-shelf tools.
Until we have silver bullets for ML, portfolios of copper bullets addressing certain parts of the ‘kill-chain’ and tailored at certain types of deployments, as system solutions rather than algorithmic solutions, will have to be created. When investing in the creation of any of those, we shall be able to answer a few key questions:
-
What part of the ML threat landscape does the new technology mitigate? (Recall that this post focuses on an interesting challenge, but which is not the only one.)
-
Where does it fit in the ML ‘kill-chain’, i.e., at what point of interaction between the attacker and the defender does this technology attempt to make the attacker’s life harder?
-
What are the use-cases (an hence, the TAM) for which the technology can be deployed effectively?
-
In those areas, what part of the overall puzzle does it cover? Are we addressing the weakest link at all? Is there another unaddressed link which will instantly inherit the weakest-link crown if we harden the current one?
-
If the solution implements a generic function (i.e., one that is not tied to a use-case), such as in the case of COTS hardware, then how is it instantiated? How do the envisioned end-deployments score according to the previous questions?
As in many other areas of Security and of Engineering in general, best is the enemy of the good, and our pragmatic marketplace will reward good enough protection now over silver bullets later.
Comments
Display comments as Linear | Threaded
Efim Hudis on :
Cool analysis. I think it would be good to define different types of ai models and analysed attacks against each type separately. The waze/Google type is different than attacks against object recognition systems for example..
Hagai Bar-El on :
True, attacks against the latter are more reliant on knowing the state, and a recognition system contains a verifier that can either be tweaked by the opponent or not (and hence is either part of the solution or part of the problem...) I guess it all boils down to that ML Security will become a set of approaches (then technologies and products) each applicable to a set of use-cases, before we can offer a generic panacea.